Customer Loan Default Prediction
Predictive modeling
The goal is to build a model that predicts a probability that a given customer will default on a loan. A customer profile consists of a list of bank transactions preceding the loan request. Each transaction is either a debit (money going out of account, negative values) or credit (money coming into account, positive values).
Customer profile (attributes, 15000 customers total):
Id: id of each customerdates: dates of each transactiontransaction_amount: numpyarray of credits and debits, length varies across different customers (predictions will be primarily based oninformation inthis array)days_before_request_days: before loan request for each transactionloan_amount: amount loaned to customer by bankloan_date: date of loan
Outcome:
isDefault: the customer pay back (isDefault=0) or not pay back (isDefault=1)
isDefault is given for the first 10000 customers. The job is to assign a probability to isDefault for the remaining 5000 customers. Train the model on the training data (instances 0-9999) and make predictions on the test data (instances 10000-14,999). The test data is the same format as training data, except it does not contain the isDefault column. The data is available here. The data can be loaded from dataset_new.pkl in Python using:
import pandas as pd
data = pd.read_pickle('dataset_new.pkl')
Construct features:
import numpy as np
from datetime import datetime
def mk_data(data, num):
features = np.zeros((data.shape[0], 16*10*3+1))
targets = np.zeros(num)
for i in range(len(data)):
dates = data[1][i][1]
trxn_amount = data[2][i][1]
loan_amount = data[4][i][1]
loan_date = data[5][i][1]
if i < num:
targets[i] = data[6][i][1]
features[i][-1] = loan_amount
trxn_grps = dict()
for j in range(len(trxn_amount)):
amount = trxn_amount[j][0]
days = (datetime.strptime(loan_date, '%Y-%m-%d') - datetime.strptime(dates[j], '%Y-%m-%d')).days
day_idx = min(days//10, 9)
if amount <= -50000:
amount_idx = 0
elif amount > -50000 and amount <= -20000:
amount_idx = 1
elif amount > -20000 and amount <= -10000:
amount_idx = 2
elif amount > -10000 and amount <= -5000:
amount_idx = 3
elif amount > -5000 and amount <= -2000:
amount_idx = 4
elif amount > -2000 and amount <= -1000:
amount_idx = 5
elif amount > -1000 and amount <= -500:
amount_idx = 6
elif amount > -500 and amount <= 0:
amount_idx = 7
elif amount > 0 and amount <= 500:
amount_idx = 8
elif amount > 500 and amount <= 1000:
amount_idx = 9
elif amount > 1000 and amount <= 2000:
amount_idx = 10
elif amount > 2000 and amount <= 5000:
amount_idx = 11
elif amount > 5000 and amount <= 10000:
amount_idx = 12
elif amount > 10000 and amount <= 20000:
amount_idx = 13
elif amount > 20000 and amount <= 50000:
amount_idx = 14
else:
amount_idx = 15
idx = day_idx * 16 + amount_idx
if idx not in trxn_grps:
trxn_grps[idx] = []
trxn_grps[idx].append(amount)
for day_idx in range(9, -1, -1):
for amount_idx in range(15, -1, -1):
idx = day_idx * 16 + amount_idx
if idx in trxn_grps and len(trxn_grps[idx]) > 0:
amounts = trxn_grps[idx]
if day_idx == 9:
features[i][idx*3] = 0
features[i][idx*3+1] = len(amounts)
features[i][idx*3+2] = np.sum(amounts)
else:
features[i][idx*3] = 0
features[i][idx*3+1] = features[i][(idx+1)*3+1] + len(amounts)
features[i][idx*3+2] = features[i][(idx+1)*3+2] + np.sum(amounts)
else:
if day_idx == 9:
features[i][idx*3] = 1
features[i][idx*3+1] = 0
features[i][idx*3+2] = 0
else:
features[i][idx*3] = features[i][(idx+1)*3] + 1
features[i][idx*3+1] = features[i][(idx+1)*3+1]
features[i][idx*3+2] = features[i][(idx+1)*3+2]
return features, targets
Train test split:
x_train = features[:10000, :]
x_val = features[10000:10500, :]
x_test = features[10000:, :]
y_train = targets[:10000]
y_val = targets[10000:]
from sklearn.ensemble import GradientBoostingClassifier
clf = GradientBoostingClassifier(n_estimators=160)
from sklearn.model_selection import StratifiedKFold
from sklearn.metrics import roc_curve, auc
tprs = np.zeros([10,100])
aucs = np.zeros([10])
mean_fpr = np.linspace(0, 1, 100)
cv = StratifiedKFold(n_splits=10)
i=0
for train, test in cv.split(x_train, y_train):
probas_ = clf.fit(x_train[train], y_train[train]).predict_proba(x_train[test])
fpr, tpr, thresholds = roc_curve(y_train[test], probas_[:, 1])
tprs[i,:] = np.interp(mean_fpr, fpr, tpr)
roc_auc = auc(fpr, tpr)
aucs[i] = roc_auc
i+=1
import matplotlib.pyplot as plt
plt.plot(mean_fpr,np.mean(tprs,axis=0))
plt.plot([0,1],[0,1])
plt.title('Mean ROC Curve : '+str(np.mean(aucs)))
plt.show()
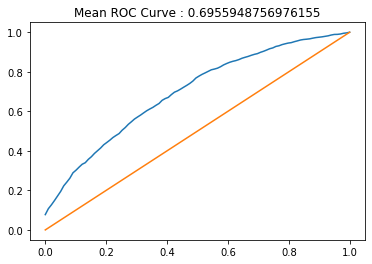
Fit the model:
clf.fit(x_train, y_train)
probas_=clf.predict_proba(x_val)
fpr, tpr, thresholds = roc_curve(y_val, probas_[:, 1])
roc_auc = auc(fpr, tpr)
plt.plot(fpr,tpr)
plt.plot([0,1],[0,1])
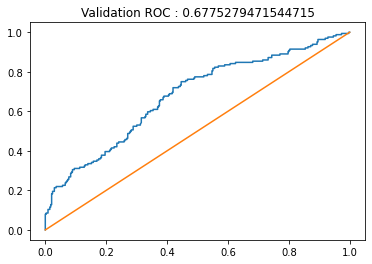
plt.title('Validation ROC : '+str(roc_auc))
plt.show()
Validation ROC curve of the model:
Top 5 most important features:
print(clf.feature_importances_.argsort()[-5:][::-1])
[480 21 24 27 368]
Make prediction using clf.predict_proba(x_test)[:, 1].